
K Means and KNN are both machine learning algorithms. One is an Unsupervised algorithm used for clustering while the other is a supervised algorithm used for classification. But because of their name similarities, many newbies get confused. So, in this article we will see the complete difference between K means and Knn machine learning, also we will see how they work. Hope you will like it ☺
What is K-Means clustering in Machine learning?
K-Means is a clustering algorithm, which is a part of unsupervised machine learning(data with no labels). It is used to create clusters out of lots of unlabeled data points where data holding a similar property or pattern are stored in the same cluster. “K” in K means represents the number of clusters it forms, which is decided by the practitioner.
For example, if you have data of lots of fruit without labels(means you just have their property like shape, size, color, taste, etc and you don’t know which fruit it is) then based on their property it will create different clusters and put the fruits with same property in one cluster and others in other clusters.
Also Read –> What is Docker and why we need a beginners guide
K-Means is an unsupervised machine learning technique that clusters data (data with no labels). It is used to construct clusters from a large number of unlabeled data points in which data with similar properties or patterns are kept together. The number of clusters it produces, which is determined by the practitioner, is represented by the letter “K” in K. For example, if you have data of many fruits without labels (that is, you only know their properties such as shape, size, color, taste, and so on but not which fruit it is), it will create different clusters based on their properties and place fruits with similar properties in one cluster and those with different properties in another.

How does KMeans work?
It is very easy to understand how K means work. To understand it better, let’s see it’s process step by step.
Step 1 → After collecting and feeding the data to the model we first decide the value of “K” which is nothing but the number of clusters. The value of “K” is generally decided on the basis of understanding of domain and data. There is also one other method to decide the value of “K” which we will discuss later in this article.
Step 2 → Then we randomly choose the K number of Centroid (center of data points, initially we choose it randomly so it is actually not in a center) which represents the center of a particular cluster. For example, if we choose K’s value to be 2 then we will have two clusters and each cluster will have one Centroid.
Step 3 → Then we calculate the distance of each data point from each centroid we created. And then we assign the data points to a certain cluster based on the closest distance it has from a centroid. For example If the distance of a data point ‘P’ from the centroid “A” is 5 and from the centroid “B” is 7 then the data point ‘P’ will be assigned to centroid “A”.
Step 4 → After we assign each data point to its closest cluster, we then calculate the actual centroid of each cluster.
Step 5 → And after that we repeat the step 3 and 4 until it’s fully optimized.
Step 1: After gathering and feeding data to the model, we must first determine the value of “K,” which is simply the number of clusters. The value of “K” is usually determined by a thorough study of the domain and data. There’s another way to figure out the value of “K,” which we’ll go over later in this post. Step 2: Next, we pick the K number of Centroids (the center of data points, which is originally chosen at random, so it is not in the center) that reflect the cluster’s center at random. For example, if we set K to 2, we will have two clusters, each with its own Centroid.

Now we will look at the other method for choosing the best “K” value for your model. The method is called the “Elbow” method, quite a weird name right! XD, we will see why it is.
We decide the best value of K by first calculating WCSS(Within Cluster Sum of Square) of a model with different values of “K” .
(WCSS measures the sum of squared average distance of each point from its centroid within a cluster. The smaller the value the more compact it is and vice versa. In short this metric is used to measure the cluster’s evaluation, if you want to learn more about it then you can read it here.)
And then we plot the line graph out of it and search for a point where wcss score suddenly stops decreasing, usually this forms a curve like an elbow and that’s the reason it’s called elbow curve or elbow method.
We’ll now look at the second approach for determining the appropriate “K” value for your model. The approach is known as the “Elbow” technique, which is a strange name. We’ll see why that is, XD. We determine the optimal K value by calculating the WCSS (Within Cluster Sum of Square) of a model with various K values. (WCSS calculates the sum of each point’s squared average distance from the cluster’s centroid.) The smaller the value, the smaller the value, and vice versa. In a nutshell, this statistic is used to assess the cluster’s performance; if you want to learn more about it, click here.) Then we create a line graph out of it and look for a place where the wcss score abruptly stops.

What is KNN Classification?
K NN stands for K nearest neighbor, which is a classification algorithm of Supervised Learning. It is used to classify a data point to a certain class, based on its property and patterns, for example, if you have two classes, Dog, and Cat and you passed an image of a cat then it will be classified as a cat class.
Just like K means, “K” in Knn also has a meaning, actually, it is a parameter that refers to the number of nearest neighbors to include in the majority of the voting process.
Also Read –> Deep learning complete guide for beginners without math
How does KNN work?
To understand how K NN works let’s see its process step by step
Step 1 → First we choose the data point we want to classify, let’s name it “M” for a while.
Step 2 → After that just like K Means we then decide the value of K but here it is not the value for cluster, instead it is the number of nearest neighbours to a point we want to classify which in our case is “M”. The value of K is decided by the practitioner, depending on the data and domain.
Also it is believed to be good practise to keep the value of “K” as an odd number because we classify any value to a class based on the maximum number of nearest data points of certain class to the point we want to classify and if we choose the value of “K” as an even number then we it could
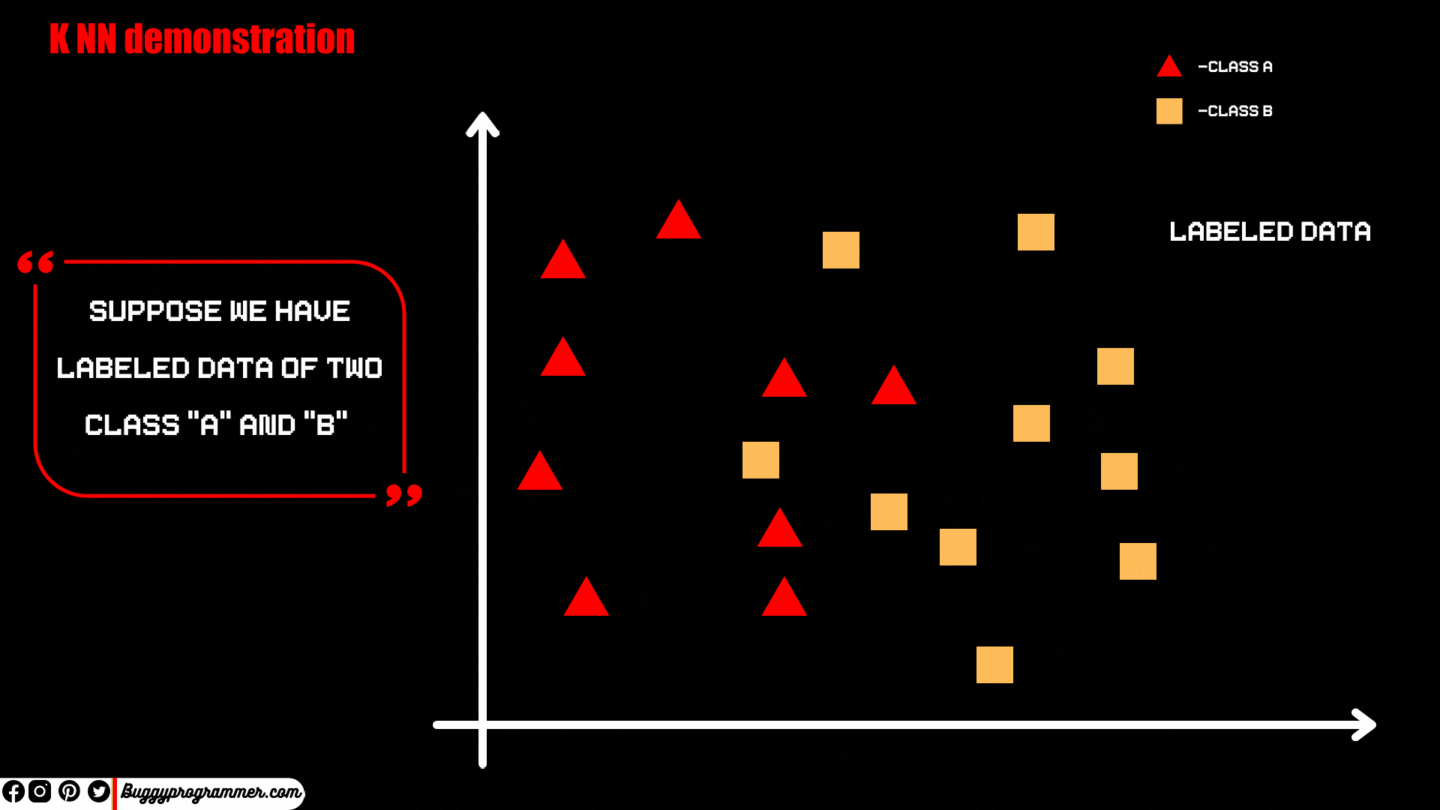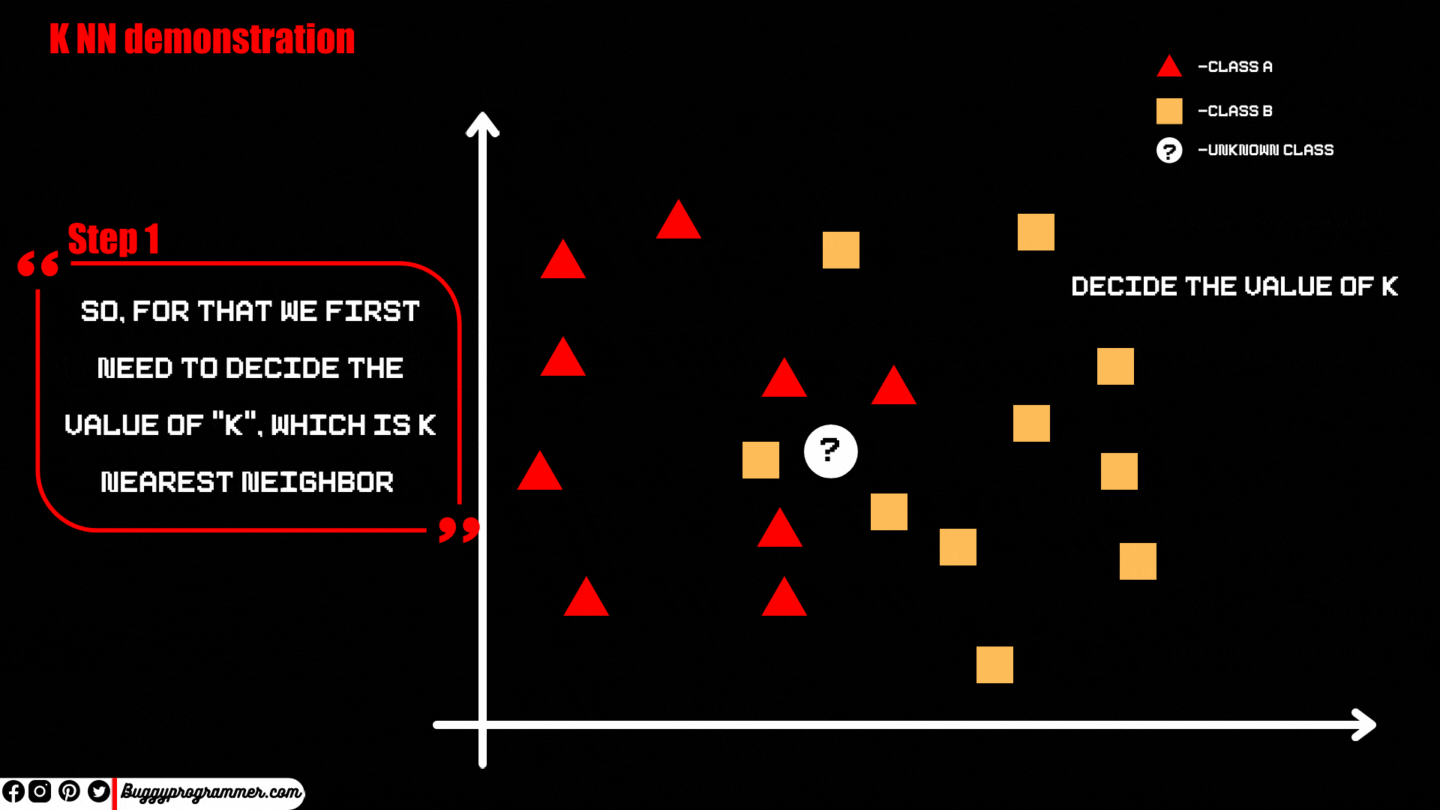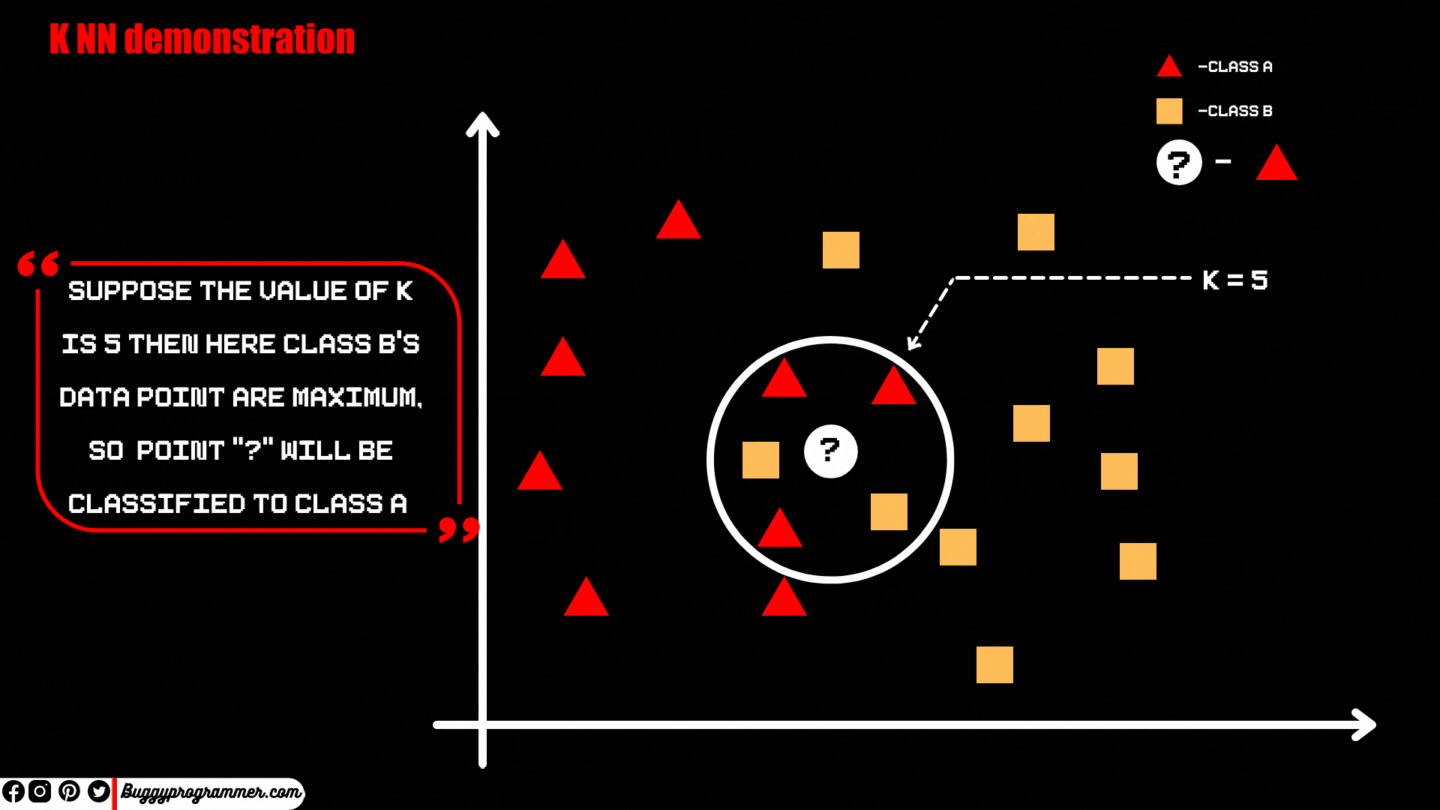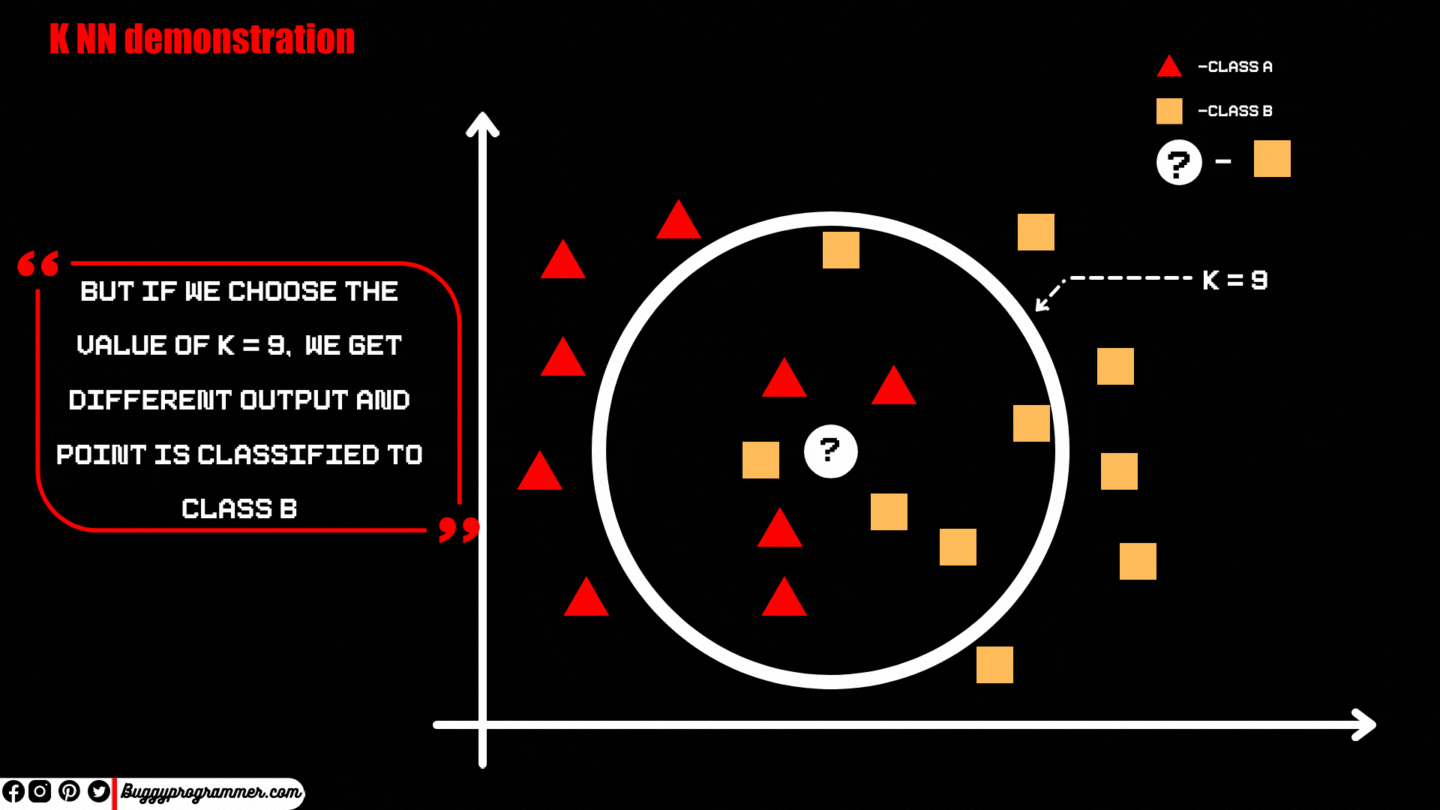
For example, if you want to classify the point “P” to the class “A” or “B” and the value of “K” is 5 then the model will pick 5 nearest values to the point “A”. Those points could be from any or both class, depending on its position
Step 3 → After deciding the value of “K”, (which is K nearest data points of available class to the data points we are classifying “M”) then let’s create an imaginary circle covering those K values around the point “M”. And now we will count whose class’s data points are maximum inside the circle. The data point will be assigned to the class which has the maximum data point inside that circle.
Step 1: First, we pick the data point we wish to categorise; for now, let’s call it “M.” Step 2: After that, just as with K Means, we determine the value of K, but this time it is the number of nearest neighbors to a location we wish to categorize, which in our instance is “M.” The practitioner determines the value of K based on the data and domain. Also, keeping the value of “K” as an odd number is thought to be good practice because we classify any value to a class based on the maximum number of nearest data points of a certain class to the point we want to classify, and if we choose the value of “K” as an even number, we risk overclassifying the point. Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN. How KNN works, How KNN works
Difference between K Means and KNN?
The big main difference between K means and KNN is that K means is an unsupervised learning clustering algorithm, while KNN is a supervised learning classification algorithm. K means creates classes out of unlabeled data while KNN classifies data to available classes from labeled data.
Also, read –> Difference between Java and Javascript
Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN, Difference between K Means and KNN

Data Scientist with 3+ years of experience in building data-intensive applications in diverse industries. Proficient in predictive modeling, computer vision, natural language processing, data visualization etc. Aside from being a data scientist, I am also a blogger and photographer.



